xCluster replication
YugabyteDB provides synchronous replication of data in universes dispersed across multiple (three or more) data centers by using the Raft consensus algorithm to achieve enhanced high availability and performance. However, many use cases do not require synchronous replication or justify the additional complexity and operation costs associated with managing three or more data centers. For these needs, YugabyteDB supports two-data-center (2DC) deployments that use cross-cluster (xCluster) replication built on top of change data capture (CDC) in DocDB.
For details about configuring an xCluster deployment, see xCluster deployment.
xCluster replication of data works across YSQL and YCQL APIs because the replication is done at the DocDB level.
Supported deployment scenarios
A number of deployment scenarios is supported.
Active-passive
The replication could be unidirectional from a source universe (also known as producer universe) to one target universe (also known as consumer universe or sink universe). The target universes are typically located in data centers or regions that are different from the source universe. They are passive because they do not take writes from the higher layer services. Usually, such deployments are used for serving low-latency reads from the target universes, as well as for disaster recovery purposes.
The following diagram shows the source-target deployment architecture:
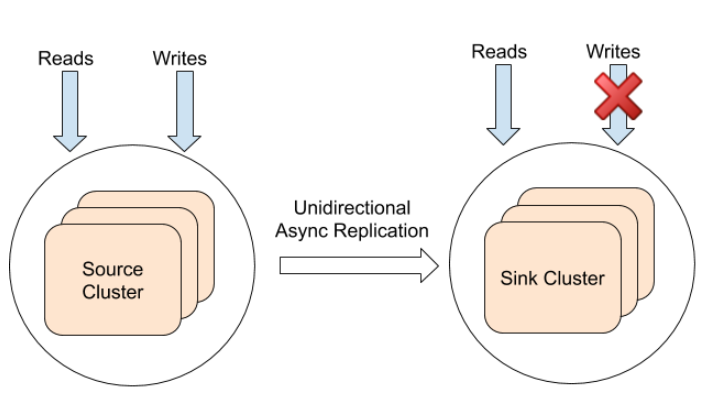
Active-active
The replication of data can be bidirectional between two universes, in which case both universes can perform reads and writes. Writes to any universe are asynchronously replicated to the other universe with a timestamp for the update. If the same key is updated in both universes at a similar time window, this results in the write with the larger timestamp becoming the latest write. In this case, the universes are all active, and this deployment mode is called a multi-master or active-active deployment.
The multi-master deployment is built internally using two source-target unidirectional replication streams as a building block. Special care is taken to ensure that the timestamps are assigned to guarantee last writer wins semantics and the data arriving from the replication stream is not rereplicated.
The following is the architecture diagram:
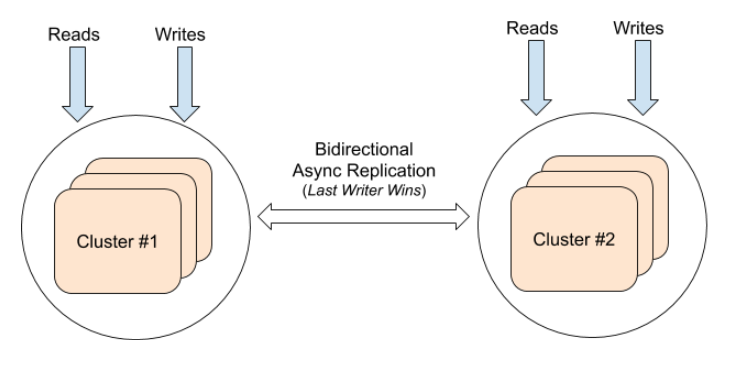
Not supported deployment scenarios
A number of deployment scenarios are not yet supported in YugabyteDB.
Broadcast
This topology involves one source universe sending data to many target universes. See #11535 for details.
Consolidation
This topology involves many source universes sending data to one central target universe. See #11535 for details.
More complex topologies
Outside of the traditional 1:1 topology and the previously described 1:N and N:1 topologies, there are many other desired configurations that are not currently supported, such as the following:
- Daisy chaining, which involves connecting a series of universes as both source and target, for example:
A<>B<>C - Ring, which involves connecting a series of universes in a loop, for example:
A<>B<>C<>A
Some of these topologies might become naturally available as soon as Broadcast and Consolidation use cases are resolved, thus allowing a universe to simultaneously be both a source and a target to several other universes. For details, see #11535.
Features and limitations
A number of features and limitations are worth noting.
Features
- The target universe has at-least-once semantics. This means every update on the source is eventually replicated to the target.
- Updates are timeline-consistent. That is, the target data center receives updates for a row in the same order in which they occurred on the source.
- Multi-shard transactions are supported, but with relaxed atomicity and global ordering semantics, as per Limitations.
- For active-active deployments, there could be updates to the same rows, on both universes. Underneath, a last-writer-wins conflict resolution semantic could be used. The deciding factor is the underlying hybrid time of the updates, from each universe.
Impact on application design
Because 2DC replication is done asynchronously and by replicating the WAL (and thereby bypassing the query layer), application design needs to follow these patterns:
-
Avoid
UNIQUEindexes and constraints (only for active-active mode): Because replication is done at the WAL-level, there is no way to check for unique constraints. It is possible to have two conflicting writes on separate universes which would violate the unique constraint and cause the main table to contain both rows, yet the index to contain only one row, resulting in an inconsistent state. -
Avoid triggers: Because the query layer is bypassed for replicated records, the database triggers are not fired for those records and can result in unexpected behavior.
-
Avoid serial columns in primary key (only for active-active mode): Because both universes generate the same sequence numbers, this can result in conflicting rows. It is recommended to use UUIDs instead.
Limitations
There is a number of limitations in the current xCluster implementation.
Transactional semantics
- Transactions from the source are not applied atomically on the target. That is, some changes in a transaction may be visible before others.
- Transactions from the source might not respect global ordering on the target. While transactions affecting the same shards are guaranteed to be timeline consistent even on the target, transactions affecting different shards might end up being visible on the target in a different order than they were committed on the source.
This is tracked in #10976.
Bootstrapping target universes
- Currently, it is your responsibility to ensure that a target universe has sufficiently recent updates, so that replication can safely resume. In the future, bootstrapping the target universe will be automated, which is tracked in #11538.
- Bootstrap currently relies on the underlying backup and restore (BAR) mechanism of YugabyteDB. This means it also inherits all of the limitations of BAR. For YSQL, currently the scope of BAR is at a database level, while the scope of replication is at table level. This implies that when bootstrapping a target universe, you automatically bring any tables from source database to the target database, even the ones on which you might not plan to actually configure replication. This is tracked in #11536.
DDL changes
- Currently, DDL changes are not automatically replicated. Applying commands such as
CREATE TABLE,ALTER TABLE, andCREATE INDEXto the target universes is your responsibility. DROP TABLEis not supported. You must first disable replication for this table.TRUNCATE TABLEis not supported. This is an underlying limitation, due to the level at which the two features operate. That is, replication is implemented on top of the Raft WAL files, while truncate is implemented on top of the RocksDB SST files.- In the future, it will be possible to propagate DDL changes safely to other universes. This is tracked in #11537.
Safety of DDL and DML in active-active
- Currently, certain potentially unsafe combinations of DDL and DML are allowed. For example, in having a unique key constraint on a column in an active-active last writer wins mode is unsafe because a violation could be introduced by inserting different values on the two universes, since each of these operations is legal in itself. The ensuing replication can, however, violate the unique key constraint and cause the two universes to permanently diverge and the replication to fail.
- In the future, it will be possible to detect such unsafe combinations and issue a warning, potentially by default. This is tracked in #11539.
Kubernetes
- Technically, replication can be set up with Kubernetes-deployed universes. However, the source and target must be able to communicate by directly referencing the pods in the other universe. In practice, this either means that the two universes must be part of the same Kubernetes cluster or that two Kubernetes clusters must have DNS and routing properly setup amongst themselves.
- Being able to have two YugabyteDB universes, each in their own standalone Kubernetes cluster, communicating with each other via a load balancer, is not currently supported, as per #2422.
Cross-feature interactions
A number of interactions across features is supported.
Supported
- TLS is supported for both client and internal RPC traffic. Universes can also be configured with different certificates.
- RPC compression is supported. Note that both universes must be on a version that supports compression, before a compression algorithm is enabled.
- Encryption at rest is supported. Note that the universes can technically use different Key Management Service (KMS) configurations. However, for bootstrapping a target universe, the reliance is on the backup and restore flow. As such, a limitation from that is inherited, which requires that the universe being restored has at least access to the same KMS as the one in which the backup was taken. This means both the source and the target must have access to the same KMS configurations.
- YSQL colocation is supported.
- YSQL geo-partitioning is supported. Note that you must configure replication on all new partitions manually, as DDL changes are not replicated automatically.
- Source and target universes can have different number of tablets.
- Tablet splitting is supported on both source and target universes.
Not currently supported
- Savepoints are not supported, as per #14308.
Transactional guarantees
Not globally ordered
Transactions on non-overlapping rows may be applied in a different order on the target universe, than they were on the source universe.
Last writer wins
In case of active-active configurations, if there are conflicting writes to the same key, then the update with the larger timestamp is considered the latest update. Thus, the deployment is eventually consistent across the two data centers.